1.IO多路复用概述
为什么需要多路复用?
首先,在网络编程中,要想实现并发处理IO事件,可以选择多线程以及线程池等。但是随着并发量的增大以及IO操作会出现阻塞的特性,多线程并不能很好的处理这些IO事件。所以急需一种新的技术,能够解决IO操作的等待问题,并且支持大量并发。
什么是IO多路复用?
IO多路复用是内核提供一种特殊机制,它能够获取一个文件描述符集合,这个集合中的文件描述符已经准备好读写操作了,所以不会出现阻塞的问题,所以能够极大地提高IO操作效率。
IO多路复用有哪些方式?
- select:支持最大1024个fd的IO多路复用操作,属于跨平台接口,采用线性结构存储fd。
- poll:只在linux系统中的接口,采用线性结构存储fd,没有最大限制。
- epoll:只在linux系统中的接口,采用红黑树结构存储fd,没有最大限制,而且复制数据少,
2.select
IO多路复用的原理是:根据内核检测到fd的读或写已就绪,传达到用户态,用户只调用已经就绪的fd的读写操作,这样就不会有阻塞IO的情况。
理论
select是最易于理解的方式,所以它的性能不会太高。select用一个1024bit标志位的结构来管理fd的状态(判断是否就绪)。内核会线性查询这1024bit中的内容,然后如果某个fd已就绪,那么内核会修改标志位,告诉用户这个fd已准备就绪,可以操作。
函数原型
#include <sys/select.h>
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval * timeout);
参数:
**nfds**:委托内核检测的这三个fd集合中的最大文件描述符+1**readfds**:文件描述符的集合,内核只检测这个文件描述符集合的读缓冲区**writefds**:文件描述符的集合,内核只检测这个文件描述符集合的写缓冲区**exceptfds**:文件描述符的集合,内核只检测这个文件描述符集合的错误缓冲区
返回值:
**0**:超时,未检测到就绪的文件描述符**-1**:错误,函数调用失败**大于0**:函数调用成功,返回集合中已就绪的文件描述符的总个数
另外,fd_set还需要一些相关操作函数:
// 将文件描述符fd从set集合中删除 == 将fd对应的标志位设置为0
void FD_CLR(int fd, fd_set *set);
// 判断文件描述符fd是否在set集合中 == 读一下fd对应的标志位到底是0还是1
int FD_ISSET(int fd, fd_set *set);
// 将文件描述符fd添加到set集合中 == 将fd对应的标志位设置为1
void FD_SET(int fd, fd_set *set);
// 将set集合中, 所有文件文件描述符对应的标志位设置为0, 集合中没有添加任何文件描述符
void FD_ZERO(fd_set *set);
3.poll
IO多路复用的原理是:根据内核检测到fd的读或写已就绪,传达到用户态,用户只调用已经就绪的fd的读写操作,这样就不会有阻塞IO的情况。
理论
poll的原理和select是很相似的,都是委托内核线性查找文件描述符集合,判断它的读写缓冲区,然后返回给用户可以操作的文件描述符。与select不同的是,select采用一种标志位的手段,而poll采用一种结构体数组的手段,具体实现看下面的函数原型。
还有几点不同的是:
select最大限制为1024,是内核决定的,而poll的数量是用户设置的。
select可以跨平台使用,而poll只能用在linux里。
函数原型
#include <poll.h>
// 每个委托poll检测的fd都对应这样一个结构体
struct pollfd {
int fd; /* 委托内核检测的文件描述符 */
short events; /* 委托内核检测文件描述符的什么事件 */
short revents; /* 文件描述符实际发生的事件 -> 传出 */
};
struct pollfd myfd[100];
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
参数:
-
**fds**:struct pollfd类型的数组。 -
**fd**:委托内核检测的文件描述符**events**:委托内核检测文件描述符的什么事件,相关取值见下面的表**revents**:文件描述符实际发生的事件 -> 传出,相关取值见下面的表-
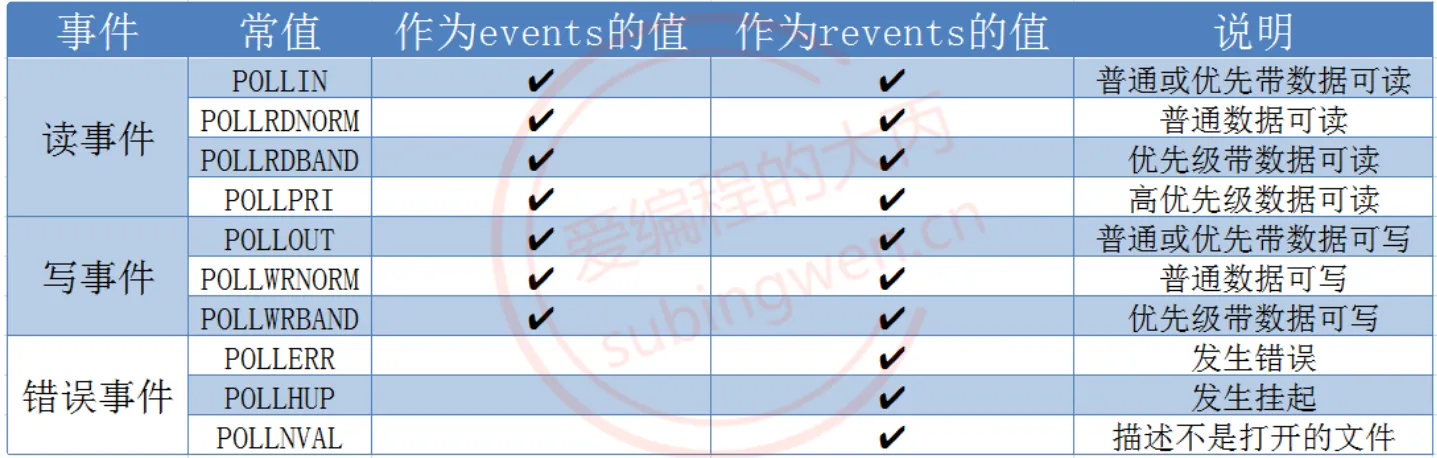
**nfds**: 这是第一个参数数组中最后一个有效元素的下标 + 1**timeout**:超时时间
4.epoll
IO多路复用的原理是:根据内核检测到fd的读或写已就绪,传达到用户态,用户只调用已经就绪的fd的读写操作,这样就不会有阻塞IO的情况。
理论
epoll是select和poll的升级版,相比于这两种方案,epoll改进了工作方式,因此工作更高效。具体区别如下:
- 对于待检测的文件描述符集合select和poll采用线性方式处理,而epoll采用红黑树的结构处理
- select和poll采用线性方式扫描待检测集合,集合越大,扫描越慢,而epoll采用回调机制,效率和集合大小无关
- select和poll需要频繁的拷贝数据(在用户态和内核态之间),而epoll采用共享内存的方式(基于mmap的内存映射)。(从源码上看并没有实现mmap,还是会有数据的拷贝,可能有些系统实现了mmap,所以这条有些争议)
- 在返回给用户的文件描述符中,select和poll需要再次检查哪些文件描述符是可以操作的,而epoll直接返回的就是可操作的文件描述符。
函数原型
在epoll中一共提供是三个API函数,分别处理不同的操作,函数原型如下:
#include <sys/epoll.h>
// 创建epoll实例,通过一棵红黑树管理待检测集合
int epoll_create(int size);
// 管理红黑树上的文件描述符(添加、修改、删除)
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
// 检测epoll树中是否有就绪的文件描述符
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
**epoll_create()**函数的作用是创建一个红黑树模型的实例,用于管理待检测的文件描述符的集合。
int epoll_create(int size);
size在新版本中是一个可忽略的值,大于0即可,在旧版本(2.6.8之前)中是创建红黑树的大小。
**epoll_ctl()**函数的作用是管理红黑树实例上的节点,可以进行添加、删除、修改操作。
// 联合体, 多个变量共用同一块内存
typedef union epoll_data {
void *ptr;
int fd; // 通常情况下使用这个成员, 和epoll_ctl的第三个参数相同即可
uint32_t u32;
uint64_t u64;
} epoll_data_t;
struct epoll_event {
uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
参数:
**epfd**:epoll_create() 函数的返回值,通过这个参数找到epoll实例-
**op**:这是一个枚举值,控制通过该函数执行什么操作 -
**EPOLL_CTL_ADD**:往epoll模型中添加新的节点**EPOLL_CTL_MOD**:修改epoll模型中已经存在的节点**EPOLL_CTL_DEL**:删除epoll模型中的指定的节点
**fd**:文件描述符,即要添加/修改/删除的文件描述符-
**event**:epoll事件,用来修饰第三个参数对应的文件描述符的,指定检测这个文件描述符的什么事件 -
**events**:委托epoll检测的事件
-
-
**EPOLLIN**:读事件**EPOLLOUT**:写事件**EPOLLERR**:异常事件
-
-
**data**:用户数据变量,这是一个联合体类型,通常情况下使用里边的fd成员,用于存储待检测的文件描述符的值,在调用epoll_wait()函数的时候这个值会被传出。
**epoll_wait()**函数的作用是检测创建的epoll实例中有没有就绪的文件描述符。
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout);
参数:
**epfd**:epoll_create() 函数的返回值,通过这个参数找到epoll实例**events**:传出参数, 这是一个结构体数组的地址, 里边存储了已就绪的文件描述符的信息**maxevents**:修饰第二个参数, 结构体数组的容量(元素个数)**timeout**:超时时间