深入理解计算机系统篇之链接(1):gcc/g++的编译流程
1.摘要
本文讲解一下整个编译流程,为学习链接打基础。gcc/g++编译流程一共分为四大部分:预处理、编译、汇编、链接。最后生成elf文件。gcc/g++编译工具其实包含了预处理、编译、汇编和链接,它是一个编译驱动器。
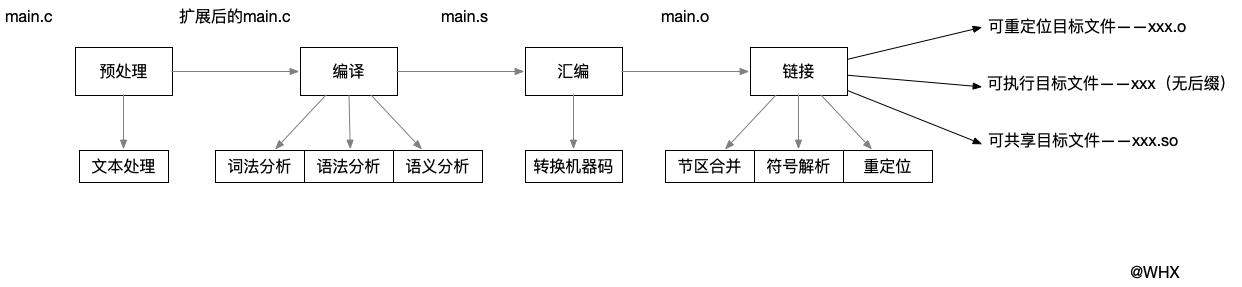
2.预处理
编译前的纯文本处理!
预处理阶段编译器执行的工作主要有:
- 将源文件中的
#<include>包含的头文件拷贝到自己文件中扩展; - 查找源文件中所有
#define定义的变量,然后进行替换; - 处理所有的预处理指令,如
#if、#else、#elif、#endif; - 删除所有注释
- 添加行号信息、文件名标识、便于调试
- 保留所有的#pragma编译指令
前四个工作都比较好理解,稍微讲一下后面两个工作,一个是添加行号,在编译出错或者报警时,我们经常可以看到错误的信息的第一个信息就是一个数字行号,用于告诉我们哪一行出现错误,便于我们调试。例如:
# 42 "main.c" 2
我们只需要了解这个行号是在预处理阶段添加的即可,不需要过多关注它的实现方式。
最后一个工作是保留所有的#pragma的编译指令,这个指令是用来告诉编译器某些状态或者让编译器执行某个特定动作的。例如最常见#pragma pack(1)结构体对齐。
注意:预处理阶段是一种完全的文本处理阶段,所有的操作都是文本的删除(注释)、保留(
#pragma)、添加(#include)等,不会存在对编译器的某些设置或某些状态改变等。最后生成的.i文件是最终要开始编译的文件。
include的搜索路径排序
include分两种方式:
#include<...>- 这种方式最先搜索系统默认路径
- 其次搜索
-I指定的路径 - 不查当前目录
#include"..."- 这种方式最先搜索当前源文件所在的目录
- 其次搜索
-I指定的路径 - 最后搜索系统默认路径
-I所指的路径是为了防止有些头文件路径找不到,在各种IDE中设置头文件路径其实原理就是用的-I将所有头文件路径包含进去,就可以找到了
出题:在编译器预处理之后会保留的指令是:A、#define,B、#include,C、#pragma,D、#if
3.编译
从人类语言到机器语言的过渡!
编译阶段分为五个小部分:词法分析、语法分析、语义分析、中间代码生成与优化、目标代码生成。前面三个部分有点像英语课上造句子的那种场景。你写的代码与英语课上的造句都需要这三步来确定对错。首先词法分析就是对具体的单词拼写判断对错,语法分析是对整个句子结构判断对错,语义分析是对整个句子内容表达是否逻辑来判断对错。映射到代码中也同样如此。
词法分析
判断你写的单词对错(代码中就是数字、符号、标识符、关键字等是否符合标准),比如标识符必须以字母或下划线开头,字符串包含非法转义,数字量违法、符号不对等。词法分析如何做到这样分析出错误的呢?它是将所有的输入切成一个一个小的token,然后拿这个token与C语言的标准进行比较,如果不符合标准就报错。
int a = 5;
[int] [a] [=] [5];
上述语句被分为四个小片段,也就是所说的token,每个token都符合标准,因此不会报错,而下列这些声明定义就会报错:
//标识符违法
int 1abd;//[int] [1abd] 1abd以数字开头,错误
int break;//[int] [break] break是关键字,错误
//字符串违法
char *s = "hi\q";//[char] [*s] [=] ["hi\q"] "hi\q"里包含非法转义,错误
//数字量违法
int a = 08;//[08]错误
float b = 3.3.5//[3.3.5]错误
int c = 0XK23;//[0XK23]错误
//符号错误
a = a@+b;//[@+]错误
以上这些都是词法分析会找到的错误,也是词法分析在编译过程中最主要的作用。
语法分析
语法就是检查结构的对错,比如语句少分号,语句块未封闭少括号之类的,它不纠结与单词的定义是否符合C语言标准,而是检查句子或者语句块的整个结构是否符合标准。语法分析在词法分析切成小的token基础上进行语法树的构建,具体构建方式是根据C语言的语法规则,将token从左到右放入语法树中,如果有问题就会报错。
正常构建过程为:
1.源代码到token
int a = 5;
[int] [a] [=] [5]
2.C语言的语法规则
规则有很多,这里简单写一下声明语句的语法规则,意思是:一个声明 = 类型 + 变量名 + 可选的初始化 + 分号。
declaration → type identifier (‘=’ expression)? ‘;’//C语言语法规则
3.构建成功的语法树(AST)
Declaration
├── Type("int")
├── Identifier("a")
└── Initializer
└── Constant(5)
而如果写的源代码有语法问题,比如:
int = 5;
根据语法规则发现type后没有identifier,于是就会报错。
下面这些类型都是语法分析检查出来的错误:
| 类型 | 描述 | 举例 |
|---|---|---|
| 括号或大括号不匹配 | 语句块没封闭 | 缺 }、缺 ) |
| 分号缺失 | 语句未结束 | 语句结束标志缺失 |
| 关键字/语句结构不完整 | if、for、while 等格式不符 |
括号、条件、主体缺失 |
| 表达式不合法 | 运算符周围不符合语法 | a = +; |
| 声明语法错误 | 类型或变量声明格式不对 | int = 5; |
| 函数定义错误 | 缺括号、缺返回类型或花括号 | main {} |
语法分析最重要的工作是AST或者说语法树的生成,它是编译阶段的核心内容,后续的语义分析以及中间代码生成都是在此基础上进行下一步工作的。
语义分析
语义分析在语法分析形成的AST基础上进行递归遍历,对每个节点执行语义分析,分析规则如下表所示:
| 节点类型 | 动作 |
|---|---|
| Declaration | 把变量注册进符号表 |
| Identifier | 查符号表验证是否存在 |
| BinaryOp(+) | 检查两侧操作数类型兼容性 |
| Return | 检查返回值类型与函数定义一致 |
| FunctionCall | 检查参数数量与类型 |
语义分析的过程大致如下:首先建立符号表,把最外层即全局变量注册进符号表,然后进入函数时也会把参数以及局部变量注册进符号表,然后遇到Identifier时就查找符号表,最后退出函数也会把局部变量以及参数从符号表中销毁;然后它也会检查各种类型是否正确,比如运算符和赋值的类型等。
未定义、未声明、类型错误等都是在语义分析阶段检查出的错误。
下面是语义分析都能检查出来的错误:
| 类别 | 检查内容 | 举例 |
|---|---|---|
| 符号检查 | 变量、函数是否已定义或声明 | x = 1; 中 x 未定义 |
| 类型检查 | 运算符或赋值的类型是否匹配 | int a; a = 3.5; |
| 作用域检查 | 标识符在作用域内是否可见 | 局部变量隐藏全局变量 |
| 函数参数匹配 | 调用时参数数量、类型是否一致 | foo(1, 2) 但定义 foo(int) |
| 控制流检查 | break, return 是否在合法位置 |
break 在 if 外面 |
| 常量性检查 | const变量是否被修改 | const int x = 1; x = 2; |
中间代码生成、优化
生成中间代码的目的是可复用、可移植、可跨平台、能够优化。开启优化等级就是在这一步进行优化的。
目标代码生成
最后根据IR生成最终的汇编文件.s
最后两步理解不够深入,不清楚AST如何到IR,IR如何到汇编的。
不过这部分有一个可移植性需要说明一下,在编译的整个流程中,在哪一个阶段之前是可移植的,之后就与目标机器绑定无法移植了:答案是在目标代码生成之前,即汇编代码生成之前,在中间代码生成与优化后还是可移植的。但具体情况上语义分析可能存在一些类型大小依赖平台,不过也不是绑定那样的关系。
4.汇编
符号(人类可理解)到二进制(计算机可理解)的跨越!
汇编阶段也有几大重要功能,首先最直观的就是将汇编语言转换成CPU的真实二进制机器码,汇编器知道映射关系,可以直接将汇编符号转换成二进制机器码,这是最直观最基础的功能。下面还有两个比较重要的功能:符号和重定位信息、节区组织,这也是生成的.o目标文件的核心信息。
目标文件的内容放在第二章讲解,这里主要了解一下汇编就是汇编符号到二进制机器码的转变。
5.链接
可执行文件的生成!
链接阶段就是整合所有需要的目标文件生成一个可执行文件或者库文件,它主要的功能有:合并节区、符号解析、地址分配以及重定位。
目标文件里的每一部分内容都比较重要,这里只介绍一下大概的功能,后续会更新对目标文件里的符号解析、重定位等的深入理解
合并节区
将.o文件的相同区域合并在一起:
main.o:
.text: main()
.data: counter = 0
math.o:
.text: add()
.data: table[10]
.text: [main][add]
.data: [counter][table]
符号解析
从所有 .symtab 中找出符号:
- 定义符号:函数、变量真正实现的地方;
- 引用符号:
extern或函数调用。
然后进行匹配
地址分配
链接器决定每个段的存放位置,例如:
| Section | 起始地址 | 示例 |
|---|---|---|
.text |
0x08000000 | 代码区 |
.data |
0x20000000 | RAM 初始化区 |
.bss |
0x20001000 | RAM 未初始化区 |
STM32 这类 MCU 中,这一步通常受 链接脚本(linker script) 控制。 脚本告诉链接器每段应放在 Flash 还是 RAM,比如.ld文件中:
SECTIONS {
.text : { *(.text*) } >FLASH
.data : { *(.data*) } >RAM
.bss : { *(.bss*) } >RAM
}
重定位
链接器现在知道所有符号的实际地址,于是把所有指令中的占位符地址替换成实际地址,修正一些偏移和跳转。
6.总结
gcc/g++的整个编译流程包括:预处理、编译、汇编、链接四大阶段。预处理是纯文本操作,负责宏展开、头文件包含、注释删除、行号添加等,不涉及任何语义逻辑。编译阶段将预处理后的文本翻译为机器可理解的中间形式,包含词法、语法、语义分析以及中间代码生成与优化等步骤,是从“源代码”到“可执行指令”的核心环节。中间代码生成使编译器具有跨平台性,优化等级(如 -O2、-O3)也在此阶段执行。随后目标代码生成阶段将IR转换为特定CPU架构的汇编指令。汇编阶段则将汇编语言转化为机器码,形成包含符号表和重定位信息的目标文件(.o)。最后链接器将多个目标文件和库合并,完成符号解析、地址分配和重定位,生成最终的可执行文件(ELF)。至此程序才真正具备运行能力。整个流程体现了从人类可读到机器可执行的逐步转化与抽象思想。
之前对编译流程的了解比较肤浅,只知道四个阶段,了解一点大致作用,这次重新学习让我对其有了更深的理解。知道预处理阶段是纯文本的展开,不做任何分析;编译阶段的词法、语法、语义才是真正对写得代码进行分析;汇编生成的一些节区和重定位信息,以及链接的符号解析和地址分配等。让我清楚了每一部分做了哪些工作,哪些报错对应出现在哪些阶段,对我以后调试问题有一定的提升。不足之处是还未对目标文件里的节区、重定位信息、符号等作进一步的了解,还要继续学习。